


When kicking off a new data analysis project, your data often comes in formats other than the native SAS dataset (*.sas7bdat file)--such as Excel spreadsheets or text files like CSV and TSV. Because SAS procedures require data in the SAS dataset format, external files must first be imported before analysis can begin.
In this tutorial, I'll show you how to import external files into SAS datasets using SAS Studio across a range of scenarios, as well as how to export those datasets in different formats. We'll start by uploading a source file to SAS Studio's cloud environment and importing it through the point-and-click interface. SAS Studio's GUI for data imports works well in most situations, especially when handling well-structured data files.
Next, we'll move on to importing raw data files using the DATA step. This approach is particularly useful when working with messy text files, such as those with inconsistent delimiters, missing values, or non-standard formatting. You'll learn how to write custom code to define input formats, handle anomalies, and transform raw data into structured SAS datasets ready for analysis.
Lastly, I'll briefly show how to export your SAS datasets to your local machine in a variety of file formats, including CSV, Excel, and plain text. This ensures your work remains portable and accessible beyond the SAS Studio's cloud environment.
Let's get started!
Get Your Data into SAS Studio
SAS Studio is a web-based application, which means your first step--regardless of your data's format--is to upload your files into SAS Studio environment. To do this, navigate to the pane on the left and click "Server Files and Folders". Then, select the folder where you want to upload your file to (typically "Files (Home)" or a subfolder within it), click "Upload", and choose local files you want to upload.

Once uploaded, the data file will appear in your selected SAS Studio directory. The next step is to import it into a SAS dataset format. In most cases--especially when the raw data is neatly organized in rows and columns, like an Excel spread sheet--you can rely on SAS Studio's point-and-click interface.
Right-click on the uploaded data file and select "Import Data". This will open a new tab for data import process.[1] On this tab, click "Change" under "OUTPUT DATA" and replace the library and dataset name. Next, fill in the row number at which data reading should start in the "Start reading data at row". This is especially important when your raw data file includes a header row, so SAS can skip it and begin reading actual data values. Following that, fill out the "Guessing rows" field. This setting determines how many number of rows SAS should scan to infer the length and data type of each column. Be sure to enter a number that is smaller than the total number of rows, but reasonably large enough to provide a reliable sample for accurate detection.

All things completed, click "Save" and "Run" buttons to begin data import. The imported SAS dataset will appear in the specified SAS library under the "Libraries" section in the navigation pane.
For typical data files, where each row represents an observation and the row values are separated by delimiters, can be directly imported using this point-and-click interface.
Aside: Creating SAS Libraries
By default, all SAS datasets are temporarily stored in the WORK library, which is automatically cleared at the end of the each session. To preserve your data, you should create a permanent library for your project and store datasets there.
To create a new SAS library, use the LIBNAME statement:
LIBNAME mydata '/path/to/your/library';
In SAS Studio, library paths begin with '/home/your-user-name/'. This username--distinct from your sign-in credentials--is specific to your SAS Studio environment and typically appears as a lowercase "u" followed by eight digits (e.g., u12345678). You can find it in the bottom-right corner of the SAS Studio interface.
Libref Naming Rules:
- Length: Up to 8 characters
- First Character: Must be a letter (A-Z, a-z) or an underscore (_)
- Subsequent Characters: Can include letters, numbers (0-9), or underscores
- Reserved Names: Avoid using reserved librefs like sashelp, sasuser, and work
To reference a dataset stored in a library, use the format: libref.dataset_name. For example, mydata.boston refers to the 'boston' dataset under the 'mydata' library.
Displaying Metadata Using PROC CONTENTS
In data analytics, metadata refers to information that describes and provides context about other data. Essentially, it's "data about data," providing:
- Descriptive Information: Details for data identification, such as titles, authors, and dataset label (if any).
- Structural Information: Details for data organization, including variable names, lengths, formats, and data types.
- Administrative Information: Details for data managements, such as file size, creation dates, and last modification dates.
SAS datasets are self-documenting, meaning that SAS automatically generates and stores metadata whenever a dataset is created or imported. To show the metadata for a SAS dataset, you can use the PROC CONTENTS procedure. For example:
PROC CONTENTS DATA=mydata.boston;RUN;

Importing Data Using SAS DATA Step
While SAS Studio's point-and-click interface handles most data import tasks, there are situations where direct instructions for reading data using the DATA step are necessary--particularly when messy or poorly structured raw data. In this section, we'll explore how to import such files using the SAS DATA step, along with practical examples.
The basic structure of a SAS DATA step for importing data looks like this:
DATA libref.dataset_name;INFILE '/path/to/your/data_source';INPUT <list-of-columns>;RUN;
Following the DATA keyword and the destination libref.dataset_name, which specifies where the new dataset will be stored--the DATA step includes two key statements:
- INFILE: Indicates the location of the raw file.
- INPUT: Defines how SAS should read and interpret the raw data values, mapping them into variables for the output dataset.
The INFILE Statement
The INFILE statement is used to specify the location of a raw data file so that SAS access and read the source data file for creating a dataset. In addition to the file path, you can include options to customize how SAS reads the data. To add an INFILE option, simply append it after file path, separated by a space.
Below are commonly used INFILE options:
- FIRSTOBS=: Specifies the row number where SAS should begin reading data.
- OBS=: Specifies the row number where SAS should stop reading data.
- ENCODING=: Defines the character encoding of the file. Common values include 'latin1', 'utf-8'.
- DLM=: Short for "delimiter." Specifies the character that separates values in the raw data file. SAS defaults to a space, but you can specify others like a comma (',') or tab ('\t'), depending on the source data format.
- DSD: Enhances delimiter handling by ignoring delimiters inside quoted strings, stripping quotation marks, and treating consecutive delimiters as missing values. If no DLM= specified, DSD assumes the delimiter is a comma, not a space. If your delimiter is different, use DLM= alongside DSD.
- MISSOVER: Prevents SAS from moving to the next line when it reaches the end of a data line with remaining variables to populate. Instead, it assigns missing values to those variables.
- TRUNCOVER: Similar to MISSOVER, but also allows partial values to populate the first unfilled variable.
Consider the following raw data file:
Name, Age, AddressJohn, 25, "123 Main St, New York, NY" Alice, 30, "456 Elm St, Los Angeles, CA" Bob, , "789 Oak St, Chicago, IL" Eva, 28, "101 Pine St, Houston, TX" Tom, 35, "202 Maple Ave, Phoenix, AZ" Sophia, 40, "303 Birch Rd, Philadelphia, PA" James, 23, "404 Cedar Blvd, San Francisco, CA"
Each line contains three values separated by commas. The first row is a header, so, we want to start reading from the second row. And suppose that we want to limit the read to the fifth row of the file. Here's the SAS program to import this file as intended:
DATA mydata.customer_address;INFILE '/home/u63368964/source/address.txt' FIRSTOBS=2 OBS=5 DSD;INPUT name $ age address $;RUN;PROC PRINT DATA=mydata.customer_address;RUN;
Observe that the INFILE statement is used with the ENCODING, FIRSTOBS, OBS, and DSD options:
- FIRSTOBS=2: Skips the header and starts reading from the second row.
- OBS=5: Stops reading at the fifth row, resulting in four observations (we excluded the first row).
- DSD: Handles quoted strings for the address field, removes quotation marks, and treats missing age values correctly.
.jpeg)
The MISSOVER and TRUNCOVER are two of the most confusing options in SAS input handling. The MISSOVER option controls how SAS behaves when a line of raw data doesn't contain enough values to populate all variables in the target SAS dataset.
By default, SAS uses the FLOWOVER option, which automatically moves to the next line of to fill in missing values if the current line of raw data file runs out. This can sometimes lead to unintended data shifts, especially when lines are meant to be read independently.
When MISSOVER is specified, SAS does not move to the next line even if the current line is shorter than expected. Instead, it assigns missing values to any remaining variables, ensuring that each line is treated as a standalone record.
To illustrate, let's consider a scenario where we're importing a raw data file such as the following:
----+----1----+----2----+----3----+----4----+LANGKAMM SARAH E0045 MechanicTORRES JAN E0029 PilotSMITH MICHAEL E0065LEISTNER COLIN E0116 MechanicTOMAS HARALDWADE KIRSTEN E0126 PilotWAUGH TIM E0204 Pilot
Now, let's read this file without the MISSOVER option:
DATA mydata.employees;INFILE '/home/u63368964/source/employees.txt';INPUT last_name $1-21 first_name $22-31 employee_id $32-36 job_title $37-45;RUN;PROC PRINT DATA=mydata.employees;RUN;
This DATA step uses column input, specifying exact positions for each variable. Without MISSOVER, SAS reads each line into the input buffer and attempts to fill all variables. If it reaches the end of a line before all variables are populated, SAS pulls in the next line and continues reading from column one--potentially mixing data from two different records. In this example, however, the default behavior corrupts the dataset by misaligning values across observations as shown below.
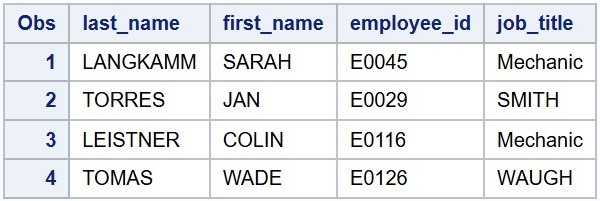
Notice that, in the second line, the values Pilot did not fully span the designated column range for job_title (columns 37-45), causing the INPUT statement to jump to the next line to complete the variable. Similarly, when reading the fifth line, SAS first moved to the sixth line to retrieve employee_id, then to the seventh line to fill in job_title.
Now, let's read the same data file using the MISSOVER option:
DATA mydata.employees;INFILE '/home/u63368964/source/employees.txt' MISSOVER;INPUT last_name $1-21 first_name $22-31 employee_id $32-36 job_title $37-45;RUN;PROC PRINT DATA=mydata.employees;RUN;

When the MISSOVER option is used in the INFILE statement, the INPUT statement does not jump to the next line when encountering a short data line. Instead, MISSOVER assigns missing values to any variables that cannot be filled from the current line. As a result, each line in the raw data is read as a separate observation in the output dataset.
However, you may still notice missing values for job_title where the value is Pilot. This occurs because, while columns 37 to 45 are designated for the variable, the value Pilot does not fully occupy that range. Without additional characters to fill the expected width, SAS leaves the variable blank.
The TRUNCOVER option works similar to MISSOVER, but with one key difference: when a line is shorter than expected, TRUNCOVER allows partial values to populate the first unfilled variable rather than assigning missing values. This can be especially useful when dealing with fixed-column input and partially filled fields.
Here's how to apply TRUNCOVER:
DATA mydata.employees;INFILE '/home/u63368964/source/employees.txt' TRUNCOVER;INPUT last_name $1-21 first_name $22-31 employee_id $32-36 job_title $37-45;RUN;PROC PRINT DATA=mydata.employees;RUN;

The INPUT Statement
Following the INFILE statement, an INPUT statement should be used to instruct SAS on how to define and populate the target variables. This involves specifying the target variable names, their types (numeric or character), and positions within the raw data from which values should be read to fill each variable.
Reading Raw Data Separated by Delimiters
List input (also called free formatted input) is a method for reading data when values in the raw data file are separated by one or more delimiters, and each line represents a complete observation. If no DLM= option is specified in the INFILE statement, SAS defaults to use spaces as delimiters.
List input is the simplest way to read data into SAS, but it comes with a few limitations:
- No skipping unwanted values: All data on a line must be read, even if some are not needed.
- Missing data representation: Missing values must be represented by a period (.).
- Character data restrictions:
- Character data must be simple, with no embedded spaces.
- Maximum length for character variables is 8.
- Limited handling for formatted values: Values should not include formatting like currency symbols (e.g., $240,000) or date strings (e.g., Mar 19, 2023).
Despite these constraints, a surprisingly many number of data files can be read simply using the list input method. To use list input, simply list the variable names in the same order they appear in the data file. Follow these rules:
- Variable names must be no longer than 32 characters.
- Each name must start with a letter or underscore (_) and contain only letters, numbers, or underscores.
- For character variables, add a dollar sign ($) after the variable name.
- Separate variable names with at least one space.
- End the statement with a semicolon.
Here's a sample raw data file:
101 John 25 M 45000102 Sarah 29 F .103 Mike . . 48000104 Anna 31 F50000105 Bob . . .
Although the data appears loosely structured, it meets the requirements for list input: character values are short and contain no embedded spaces, values are space-separated, and missing data is represented by periods. Notice that Anna's salary appears on the next line--this is acceptable because, as we discussed earlier, SAS will automatically continue reding from the next line if more values are needed to complete the observation.
Here's the SAS program to read this data:
DATA mydata.employees;INFILE '/home/u63368964/source/employees.txt';INPUT employee_id $ name $ age sex $ salary;RUN;PROC PRINT DATA=mydata.employees;RUN;

The variables employee_id, name, age, sex, and salary are listed after the INPUT keyword in the same order they appear in the data source. A dollar sign ($) after employee_id, name, and sex signifies that these are character variables. On the other hand, age and salary has no dollar signs after variable names, meaning that they are numeric.
Reading Raw Data Arranged in Columns
In an INPUT statement, column indicators refer to the numeric ranges placed after each variable name. These ranges map specific column positions in the raw data file to corresponding output variables, allowing SAS to extract values on their fixed location within each line.
For example, consider the following raw data file:
----+----1----+----2----+----3S001 John Doe 85 90 88S002 Jane Smith 92 88 95S003 Bob Johnson 78 82 80S004 Alice Lee 95 94 98S005 Emily Brown 80 85 82
To import this file and create a SAS dataset with five variables--student_id, name, math, science, and english--you can use the following DATA step:
DATA mydata.student_grades;INFILE '/home/u63368964/source/student-grades.txt';INPUT student_id $ 1-4 name $ 6-20 math science english;RUN;PROC PRINT DATA=mydata.student_grades;RUN;
In this example:
- student_id $ 1-4 tells SAS to read columns 1 through 4 as the student_id.
- name $ 6-20 reads columns 6 through 20 as the name.
- The remaining three variables--math, science, and english--are listed without column indicators, so SAS assumes they are separated by one or more spaces and reads them using list input.
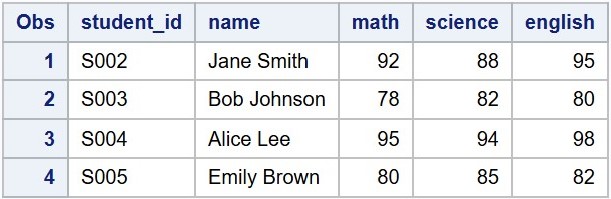
When the raw data file is neatly organized in fixed-width columns, using column indicators in the INPUT statement offers several advantages over default list input:
- Character variables can contain spaces and hold values up to 32,767 characters.
- Unnecessary values can be skipped, allowing selective reading of relevant data.
- Column order is flexible--variable-s can be read in any sequence, and the same column can be referenced multiple times.
For example, consider the following DATA step:
DATA mydata.student_grades2;INFILE '/home/u63368964/source/student-grades.txt';INPUT name $ 6-20 math science student_id $ 1-4 math_score 21-22;RUN;PROC PRINT DATA=mydata.student_grades2;RUN;
Here's how SAS processes the input:
- name $ 6-20: Reads characters from columns 6 to 20 to create name variable.
- math and science: These variables are read using list input, meaning SAS moves to the next non-whitespace values after name.
- student_id $ 1-4: SAS returns to columns 1 to 4 of the same line to populate student_id.
- math_score 21-22: Finally, SAS reads columns 21 to 22 to create math_score.

This example demonstrates how column input allows precise control over data extraction, even enabling multiple passes over the same line to retrieve values from different positions.
Reading Raw Data Not in Standard Format
Sometimes, raw data values aren't simple numeric or character types--they may appear in specific formats that are easier for humans to interpret but harder for computers to process. For example, the value "1,000,001" includes commas for readability, but without explicit instructions, SAS treats it as character string rather than a numeric value. To handle such cases, informats are used to guide SAS on how to interpret such "non-standard" data values.
The three types of informats--character, numeric, and date--have the following forms:
$informatw. /* Character */informatw.d /* Numeric */informatw. /* Date */
Where w represents the total width, d indicates the number of decimal places (applicable only to numeric data), and the dollar sign ($) means a character informat.
Dates are perhaps the most common examples of non-standard data. For example, SAS converts conventional date formats like 10-31-2023 or 31OCT23 into the number of days since January 1, 1960. This number is known as a SAS date value.
For example, let's consider the following raw data file:
----+----1----+----2----+----3----+----4-S001 01/05/2023 1,1250.00 Smartphone 0.20S002 01/06/2023 1,500.00 Laptop 2.50S003 01/07/2023 200.00 Headphones 0.10S004 01/08/2023 900.00 Tablet 0.80S005 01/09/2023 300.00 Smartwatch 0.15S006 01/10/2023 700.00 Camera 0.60S007 01/11/2023 150.00 Speaker 1.00S008 01/12/2023 400.00 Monitor 3.00S009 01/13/2023 50.00 Keyboard 0.50S010 01/14/2023 20.00 Mouse 0.20
This file contains transaction details, including ID, date, amount, product name, and weight. Each column follows a specific format--dates use MM/DD/YYYY, and amounts include commas.
To read this data properly, we use informats in the INPUT statement:
DATA mydata.sales;INFILE '/home/u63368964/source/sales.txt';INPUTtransaction_id $5.transaction_date MMDDYY11.transaction_amount COMMA10.2product_name $10.product_weight 4.2;RUN;PROC PRINT DATA=mydata.sales;RUN;

Frequently Used SAS Informats
| Informat | Width | Input Data | INPUT Statement | Results |
|---|---|---|---|---|
| Character | ||||
| $CHARw. Reads character data, while preserving blanks. |
1-32767 (default: 8 or variable length) | John Doe Jane Doe |
INPUT name $CHAR10.; | John Doe Jane Doe |
| $UPCASEw. Converts character data to uppercase. |
1-32767 (default: 8) | John Doe | INPUT name $UPCASE10.; | JOHN DOE |
| $w. Reads character data, trimming leading blanks. |
1-32767 | John Doe Jane Doe |
INPUT name $10.; | John Doe Jane Doe |
| Date, Time, and Datetime | ||||
| ANYDATEw. Reads dates in various date forms. |
5-32 (default: 9) | 1jan1961 01/01/61 |
INPUT my_date ANYDATE10.; | 366 366 |
| DATEw. Reads dates in form: ddmmmyy or ddmmmyyyy |
7-32 (default: 7) | 1jan1961 1 jan 61 |
INPUT my_date DATE10.; | 366 366 |
| DATETIMEw. Reads dates in form: ddmmmyy hh:mm:ss.ss |
13-40 (default: 18) | 1jan1960 10:30:15 1jan1961,10:30:15 |
INPUT my_dt DATETIME18.; | 37815 31660215 |
| DDMMYYw. Reads dates in from: ddmmyy or ddmmyyyy |
6-32 (default: 6) | 01.01.61 02/01/61 |
INPUT my_date DDMMYY8.; | 366 367 |
| MMDDYYw. Reads dates in form: mmddyy or mmddyyyy |
6-32 (default: 6) | 01-01-61 01/01/61 |
INPUT my_date 8.; | 366 366 |
| JULIANw. Reads Julian dates in form: yyddd or yyyyddd |
5-32 (default: 5) | 61001 1961001 |
INPUT my_date JULIAN7.; | 366 366 |
| TIMEw. Reads time in form: hh:mm:ss.ss or hh:mm |
5-32 (default: 8) | 10:30 10:30:15 |
INPUT my_time TIME8.; | 37800 37815 |
| STIMERw. Reads time in form: hh:mm:ss.ss, mm:ss.ss, or ss.ss |
1-32 (default: 10) | 10:30 10:30:15 |
INPUT my_time STIMER8.; | 630 37815 |
| Numeric | ||||
| COMMAw.d Removes embedded commas and $. Converts values in parentheses to minus. |
1-32 (default: 1) | $1,000,000.99 (1,234.99) |
INPUT income COMMA13.2; | 1000000.99 -1234.99 |
| COMMAXw.d Similar to COMMAw.d, but switches role of comma and period. |
1-32 (default: 1) | $1.000.000,99 (1.234,99) |
INPUT income COMMAX13.2; | 1000000.99 -1234.99 |
| PERCENTw. Converts percentages to numbers. |
1-32 (default: 6) | 5% (20%) |
INPUT my_num PERCENT5.; | 0.05 -0.2 |
| w.d Reads standard numeric data. |
1-32 | 1234 -12.3 |
INPUT my_num 5.1; | 123.4 -12.3 |
Aside: Extracting Date Information from Numerals
Let's consider raw data file like this:
2023 01 31 500000 350000 1500002023 02 28 520000 360000 1700002023 03 31 540000 370000 1700002023 04 30 530000 380000 1500002023 05 31 550000 390000 1600002023 06 30 560000 400000 1600002023 07 31 580000 410000 1700002023 08 31 600000 420000 1800002023 09 30 590000 415000 1750002023 10 31 610000 430000 1800002023 11 30 620000 440000 1800002023 12 31 650000 450000 200000
The raw data in this example consists of space-separated values for year, month, day, revenue, expenses, and profit. However, if you import year, month, and day as separate numeric columns, SAS will not automatically recognize them as dates. To preserve date information, you need to combine these components into a single SAS date variable using the MDY(month, date, year) function.
Here's how to implement it:
DATA month_end_closing;INFILE '/home/u63368964/source/month-end.txt';INPUT year month day revenue expenses profit;closing_date = MDY(month, day, year);RUN;PROC PRINT DATA=month_end_closing;RUN;
The MDY function constructs a SAS date value from the specified month, day, and year. By using this function, you convert the separate date components into a unified date variable (closing_date), which can then be formatted and used for time-series analysis, filtering, or other date-related operations.

Informat Modifiers
Colon Modifier
All three informats--character, numeric, and date--interpret raw data values based on the specified width. For example, $7. reads a seven-character value such as Michael. However, in practice, you may not always know the exact width of incoming values. While Michael fits neatly into $7., a longer value like Christopher would be truncated, and a shorter value like Amy might cause SAS to read into the next column, leading to incorrect data parsing.
01 01 2020 Sedan Black 10 $25,00002 01 2020 SUV White 5 $25,00003 01 2020 Hatchback Red 8 $20,00004 01 2020 Sedan Blue 12 $26,00005 01 2020 Truck Gray 7 $40,00006 01 2020 SUV Silver 6 $36,00007 01 2020 Sedan Black 15 $25,50008 01 2020 Hatchback Blue 9 $20,50009 01 2020 SUV White 10 $35,50010 01 2020 Sedan Red 20 $26,000
The example raw data file contains space-separated values representing monthly car sales. Each line is meant to include the following fields:
- Month: Numeric month (e.g., 11)
- Day: Numeric day (e.g., 01)
- Year: Four-digit year (e.g., 2020)
- Model: Type of vehicle (e.g., Sedan, SUV, Hatchback)
- Color: Vehicle color (e.g., Black, White, Red)
- Number of Sales: Quantity sold (e.g., 10)
- MSRP: Manufacturer's Suggested Retail Price, formatted with a dollar sign and comma (e.g., $25,000)
In the raw data, observe that the fourth and fifth columns--car model and color--vary in length, making it challenging to define fixed-width input fields without risking of truncation or overlap. To correctly import such values, you can use a colon modifier (:) in front of the column informats. The colon modifier instructs SAS to read up to the specified width but stop at the first space (or other delimiter) it encounters--preventing data from spilling into adjacent fields.
DATA mydata.car_sales;INFILE '/home/u63368964/source/car-sales.txt';INPUT month day year model :$15. color :$15. num_sales msrp;RUN;PROC PRINT DATA=mydata.car_sales;RUN;

Ampersand Modifier
Let's consider another example. In the raw data file below, the first column (breeds) may contain multiple words separated by spaces. In such cases, using colon modifier will not work, as it reads only up to the first space, truncating the rest of the value. For instance, an informat like breeds :$50. would read only Labrador, omitting the second word.
----+----1----+----2----+----3----+--Labrador Retriever 65 22 FriendlyGerman Shepherd 75 24 LoyalGolden Retriever 70 23 GentleBulldog 50 14 StubbornBeagle 25 15 EnergeticPoodle 45 22 IntelligentRottweiler 95 26 ConfidentYorkshire Terrier 7 7 BoldBoxer 70 25 PlayfulDachshund 11 8 CuriousSiberian Husky 60 23 IndependentDoberman Pinscher 75 26 Alert
To correctly read multi-word character values, use the ampersand modifier (&). This modifier tells SAS to treat a single space as part of the character value and to recognize two or more consecutive spaces as delimiters between variables.
DATA mydata.dog_breeds;INFILE '/home/u63368964/source/dogs.txt';INPUT breed &$50. avg_height avg_weight temper $;RUN;PROC PRINT DATA=mydata.dog_breeds;RUN;

Tilde Modifier
Lastly, it is common to encounter raw data values enclosed in double quotation marks (""), especially in CSV files. These quotation marks are typically used to group multi-word values or to preserve special characters, such as commas, within a single field. For example, suppose we want to import the following data file:
"Doe, John",25,Male,70,175"Smith, Alice",30,Female,55,160"Johnson, Bob",35,Male,80,180"Brown, Emily",28,Female,60,165"David, Michael",40,Male,85,185
The tilde modifier (~) tells SAS to treat double quotation marks ("") as part of a variable's value. This modifier is commonly used alongside the DSD option in the INFILE statement. Remember that the DSD option tells SAS to ignore commas enclosed within quotation marks while removing the quotation marks themselves during import. However, when the DSD option is combined with the tilde modifier, SAS preserves the quotation marks, while recognizing the quoted strings as a single column value.
DATA mydata.height_weight;INFILE '/home/u63368964/source/height-weight.txt' DLM=',' DSD;INPUT name ~$15. age sex $ weight height;RUN;PROC PRINT DATA=mydata.height_weight;RUN;

Reading Messy Raw Data
Column Pointer Controls
Occasionally, data files don't align neatly into columns or follow predictable lengths. In such cases, column indicators we saw earlier won't work. Instead, you'll need to use column pointers and modifiers to accurately read the data.
- @n moves the input pointer to the n-th column.
- @'character string' moves the pointer to the position immediately following the specified string.
- +n moves the pointer n-th columns forward from its current position.
For example, consider importing the following data file:
----+----1----+----2----+----3---CITY:Nome STATE:AK 5544 88 29CITY:Miami STATE:FL 9075 97 65CITY:Raleigh STATE:NC 8868 105 50
This file contains information about temperatures for the month of July for Alaska, Florida, and North Carolina. Each line includes the city, state, average high and low temperatures, and record high and low temperatures (in degrees Fahrenheit).
To import this data, you can use the following DATA step:
DATA mydata.temp;INFILE '/home/u63368964/source/temperatures.dat';INPUT @'STATE:' state $@6 city $+10avg_high 2. avg_low 2.@27record_high record_low;RUN;PROC PRINT DATA=mydata.temp;RUN;
In the DATA step,
- @'STATE:' moves the pointer just after the string 'STATE:' and reads the state abbreviation into the character variable state.
- @6 sets the pointer to column 6, where the city name begins, and reads it into city.
- +10 advances the pointer 10 columns from its current position (after reading city) to reach the average high and low temperatures.
- @27 moves the pointer to column 27 to read the record_high and record_low.

This approach allows you to extract data from files that don't follow a fixed column structure.
Line Pointer Controls
Let's explore another example where each observation spans multiple lines in the raw data.
David Shaw25189 90Amelia Serrano34165 61
In this case:
- Line 1 contains the first and last name
- Line 2 contains the age
- Line 3 contains the height and weight
Typically, SAS assumes each line of raw data corresponds to one observation. However, when data for a single observation is spread across multiple lines, SAS can automatically continue to the next line if it hasn't finished reading all variables specified in the INPUT statement. While this default behavior is convenient, it is often better to explicitly control line transitions using line pointers.
Types of Line Pointers
SAS has two types of line pointers:
- Slash (/): Moves the pointer to the next line.
- Pound-n (#n): Moves the pointer to the n-th line of the current obsrevation.
- #2 reads from the second line of the observation.
- #4 reads from the fourth line of the observation.
- / moves forward one line.
DATA mydata.height_weight;INFILE '/home/u63368964/source/height-weight.txt';INPUT first_name $ last_name $/ age#3 height weight;RUN;PROC PRINT DATA=mydata.height_weight;RUN;

Reading Multiple Observations per Line of Raw Data
By default, SAS assumes that each line of raw data contains no more than one observation. However, when multiple observations are packed into a single line, you can use double trailing at signs (@@) at the end of your INPUT statement. This line-hold specifier instructs SAS to "pause" the current line and continue reading additional observations from it until either:
- All data on the line is processed, or
- Another INPUT statement without @@ is encountered.
For example, consider the following raw data, where each line contains two observations. Each observation includes three fields: product name, price, and quantity.
Laptop 999.99 5 Tablet 499.50 10 Phone 799.90 8Monitor 199.99 12 Keyboard 49.99 20 Mouse 25.50 15Headphones 149.99 7 Webcam 89.99 5 Speaker 129.99 10
To read this kind of data correctly, you can use the following SAS program:
DATA mydata.product_sales;INFILE '/home/u63368964/source/sales.txt';INPUT product $ price quantity @@;RUN;PROC PRINT DATA=mydata.product_sales;RUN;

Conditional Input in SAS DATA Step
Sometimes, you may need to extract only a specific subset of records from a large raw data source.
----+----1----+----2----+----3----+----4----+----5Inception 2010 Action 8.8 148Avengers 2012 Action 8.0 143Interstellar 2014 Adventure 8.6 169The Dark Knight 2008 Action 9.0 152Guardians of the Galaxy 2014 Action 8.1 121Stranger Things 2016 Adventure 8.7 50Breaking Bad 2008 Drama 9.5 62The Mandalorian 2019 Adventure 8.8 55The Witcher 2019 Action 8.2 60The Last of Us 2023 Adventure 9.1 45
For example, suppose that you want to create a SAS dataset that includes only titles classified as "Action" and with a rating above 8.0 from the data source above. You can achieve this using conditional logic and a line-hold specifier in your DATA step:
DATA mydata.action_above_8;INFILE '/home/u63368964/source/movies-tv-series.txt';INPUT title &$25. year genre $ rating @;IF genre ~= 'Action' OR rating <= 8.0 THEN DELETE;INPUT duration;RUN;PROC PRINT DATA=mydata.action_above_8;RUN;
In the DATA step, there are two INPUT statements. The first INPUT statement reads the variables title, year, genre, and rating. This INPUT statement ends with a trailing at sign (@). It tells SAS to hold the current line, until executing the IF-THEN statement. Only if the observation passes the condition, SAS proceeds to read the current data line for the second INPUT statement; otherwise, the current data line would be deleted.

Here is the full list of operators that you can use with the IF-THEN statement:
| Symbolic | Mnemonic | Description | Example |
|---|---|---|---|
| = | EQ | Equal to | WHERE name = 'John'; |
| ^=, ~=, <> | NE | Not equal to | WHERE name ^= 'John'; |
| > | GT | Greater than | WHERE score > 80; |
| < | LT | Less than | WHERE score < 80; |
| >= | GE | Greater than or equal to | WHERE score >= 80; |
| <= | LE | Less than or equal to | WHERE score <= 80; |
| & | AND | Logical AND (both conditions are true) | WHERE score >= 80 AND score <= 90; |
| |, ! | OR | Logical OR (at least one of the conditions is true) | WHERE name = 'John' OR name = 'Jane'; |
| IS NOT MISSING | Checks for non-missing (non-null) values | WHERE score IS NOT MISSING; | |
| BETWEEN AND | Checks if a values is within a range (inclusive) | WHERE score BETWEEN 80 AND 90; | |
| CONTAINS | Checks if a string contains a specific substring | WHERE name CONTAINS 'J'; | |
| IN (LIST) | Checks if a value is in a specified list | WHERE name IN ('John', 'Jane'); |
Exporting and Downloading SAS Datasets
In SAS, the term "data export" refers to the process of converting native SAS dataset files (*.sas7bdat) into external file formats, such as Excel (*.xlsx) or CSV (*.csv). This conversion is often necessary when sharing data with collaborators who use other tools, integrating SAS outputs into reporting workflows, or preparing datasets for further analysis in platforms that do not support SAS file formats.
SAS Studio simplifies this task with a built-in graphical interface, eliminating the need for complex code. Whether you're a seasoned analyst or a beginner, the intuitive point-and-click functionality makes exporting data quick and accessible.
How to Export a SAS Dataset
Follow these steps to convert your SAS dataset into an external format:
- Navigate to "Libraries" section in the navigation pane.
- Right-click on the SAS dataset file that you want to export and select "Export". The Export Table window will appear.
- On the Export Table window, select where to store the exported dataset, specify proper file name, and select the output file format (e.g., *.xlsx, *.csv, etc.).
- Click "Export".

How to Download the Exported File to Your Local Machine
After exporting, the file resides in SAS Studio's cloud-based environment. To retrieve it for use on your local computer:
- Go to the "Server Files and Folders" section in the navigation pane.
- Find the exported file, right-click on it, and select "Download File".
Then the exported file will be transferred to your local downloads folder, ready for use in external applications.



{kind=link}
0 Comments